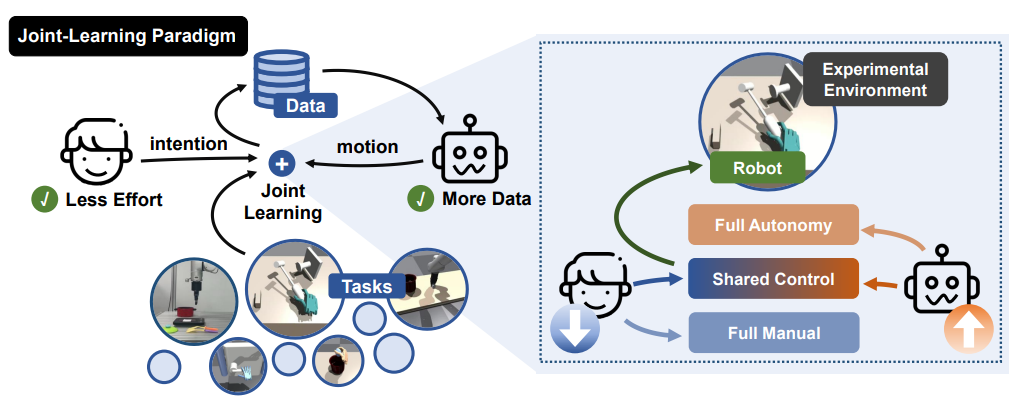
In data-collection, how to make human effort less while improving the data quality?
HAJI:
intentions.motion stability and interpolate? the details.
Acchived a 30% increase in data collection success rate and double the collection speed.
My question about this part: how to define and measure the collection speed?
Stage1: Human control as an initial but insufficient training dataset.
Stage2: Train a diffusion-model-based assistive agent, establish shared control.
Growing with more data coming in and if sufficient able to full auto.
How diffusion be used to control a robot? What the outputs of this model be like?
Answer(from below parts): generate the action for agents
DDPM
Q: What is x_k(x_0,\varepsilon)?
A: A function to get x_k from x_0 with \varepsilon?

We can get the human collected demonstration \({(s_i,a_i)}^T_{i=0}\), \(s \in \mathbb{R}^n\) is the robot state.
Q: What state exactly?
Agent: \(a=f(a^k|s,k)\).
During Data Collection, \(a^s=\gamma a^h + (1-\gamma)a^r\), where \(a^r\) is generated by agent \(a^h\) is human action, and \(a^s\) is Shared Control Action.
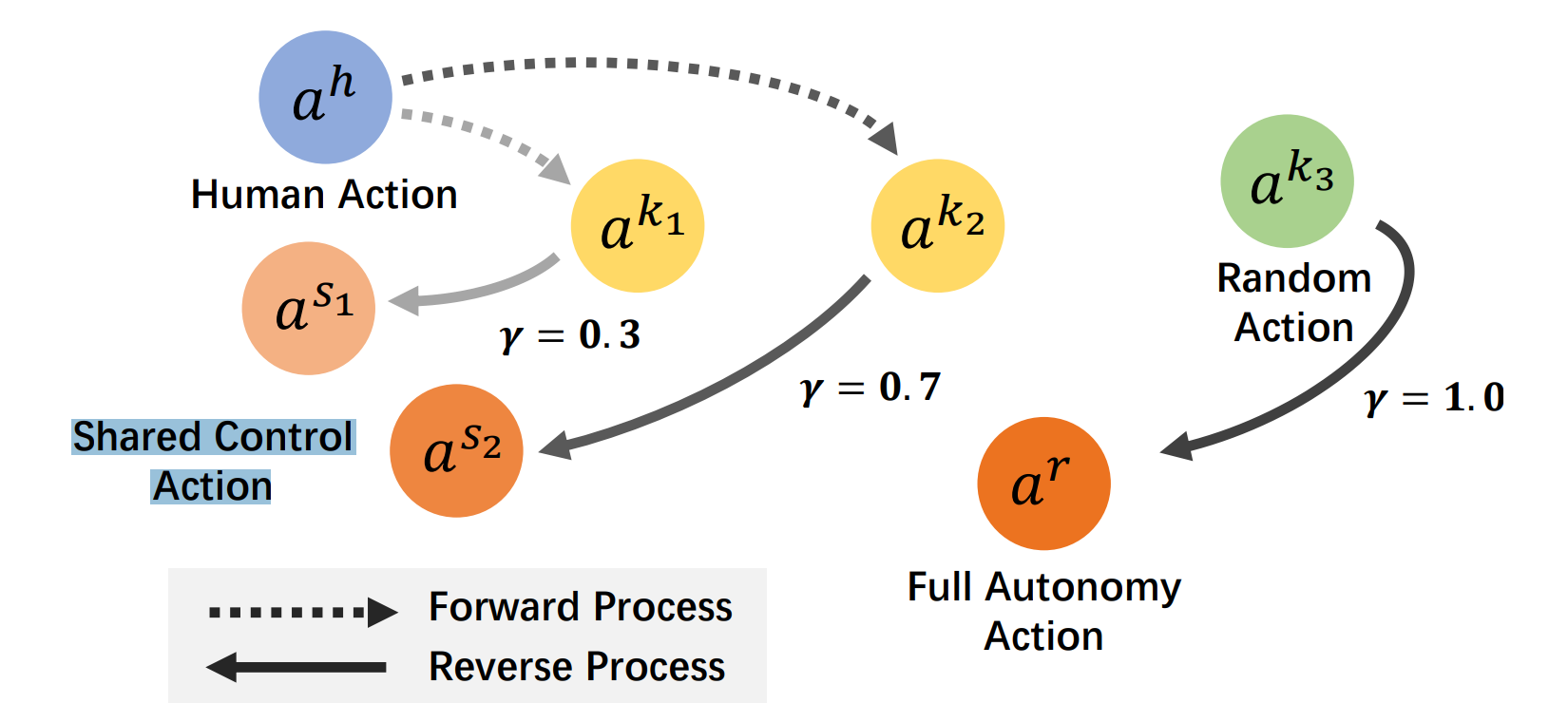
Diffussion: forward \(a^k=a^h+\varepsilon^k\), backward \(a^s=f(a^k|s,k)\)
Increase \(\gamma\) as \(k\) grow. When \(\gamma = 1.0\) \(a^s\) turn to \(a^r\), full robot auto action.
A little bit confused about H and D.
Q: May I see the code?
6
Q: What is in D? Is there only one movement for a perticular task? i.e. did we trained 6 agent? Or just one for all the tasks.
"collect as much data as possible within three minutes"
Q: Is this definition rigorous enough?
Evaluate:
For about half of my reading time, I was continuesly wondering about the meaning of training such a model as we can make the robot finish the task with our training data only. From Fig.4, I finally realized that the control process is in real time which means, after training, the human operator could be abstract, and robot will act base on the abstract instructions. This would save much time.
Is this understanding right?

But here comes another question, in III-B, we have \(a^s=\gamma a^h + (1-\gamma)a^r\).
Q1: Is this a simple weighted mean of h and r? If so, is this weighted average the average on the motion path coordinates? Intuitively imagine, does this seem unrealistic? Or is this just an abstract expression?
Q2(If 6 tasks are trained together): When \gamma=1, what will it do? Is there an input of environment(which I didn't find)?
Q3(If 6 tasks are not trained together): What will happen if trained together?
E. Real World Experiment
MLP + Diffusion, How are they connected?
Our input has changed from the original hand states and object states to the position and orientation of the robot arm end effector, as well as images from the first-person and third-person perspectives.
I didn't find where to input these things.